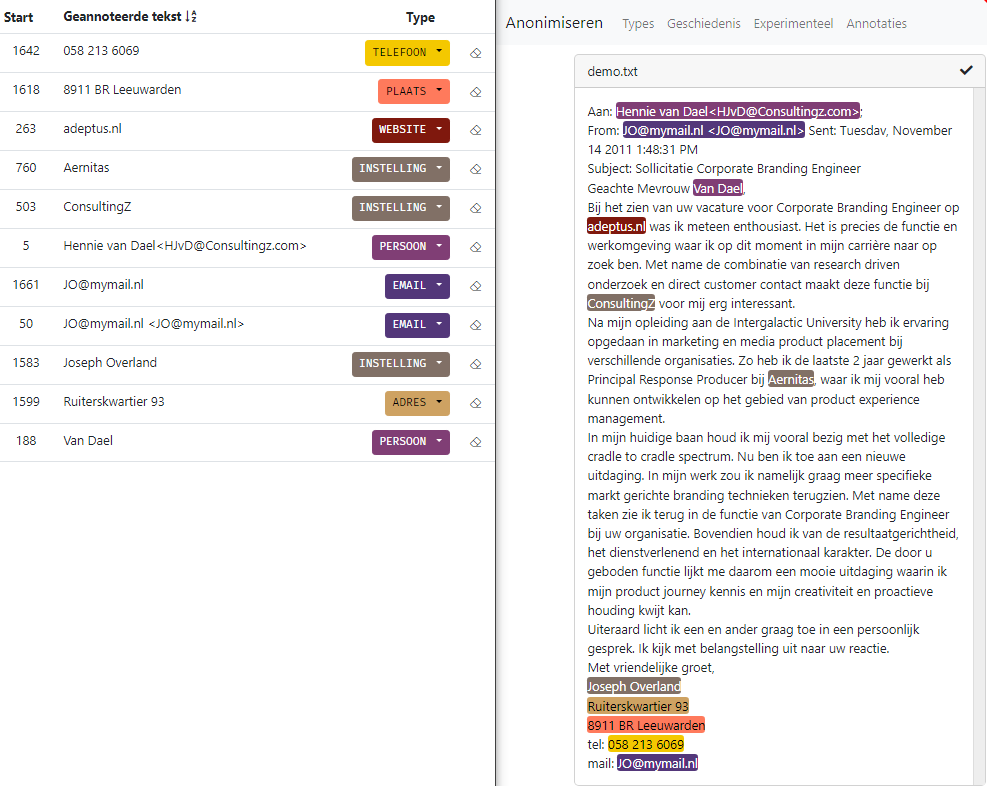
Anonymization – automated personal information removal. Semlab Anonymization is proprietary AI-driven software for removing sensitive personal data from documents in all major European languages.The software is domain independent and can be used in many different business areas like legal, government and healthcare. Users are able to share, record or publish anonymized data for publishing platforms, (clincinical) research projects and (health) records.
To optimally safeguard the sensitive nature of the data, we offer on site processing hardware to ensure no sensitive information ever leaves our customers organisation prior to anonymization.
Our approach to automatic anonymization combines both rule driven and machine learning technology based on state of the art language models. Our approch is self learnin when combined with manual sample correction and capable of processing large data volumes. In addition to extracting sensitive data, we also offer the option to add role based placeholders instead of the traditional “blackout” approach. This results in a much more readable text while still protecting any sensitive personal data.
Our solution is language independent. Currently it is used to extract sensitive information from Dutch and French legal documents, case law content and for English data analytics.
If you are interested in this application or its technology please contact us for a full demonstration of our anonymization technology.
 Anonimization product page
Anonimization product page