Binnen Semlab hebben wij al 20 jaar ervaring in het automatisch verwerken van Nederlandstalige teksten. Hierbij gebruiken we een hybride aanpak die enerzijds gebaseerd is op ontologie gedreven natuurlijke taal analyse en anderzijds gebruik maakt van language modelling. Dit laatste heeft recent een enorme vlucht genomen met de ontwikkeling van zogenaamde taalmodellen gebaseerd op transformers zoals bijvoorbeeld (chat)GPT, BERT en RoBERTa.
De kern van deze ontwikkeling is dat er nu gebruik gemaakt kan worden van de door partijen als Microsoft, Google en Facebook ontwikkelde algemene taalmodellen die zijn getraind op gespecialiseerde hardware en extreem grote datasets. Deze taalmodellen kunnen gebruikt worden als basis voor specifieke NLP toepassingen.
Bij Semlab hebben wij ons gespecialiseerd in het aanpassen van deze taalmodellen voor praktische toepassingen bij onze klanten. Dit komt neer op grofweg de volgende taken:
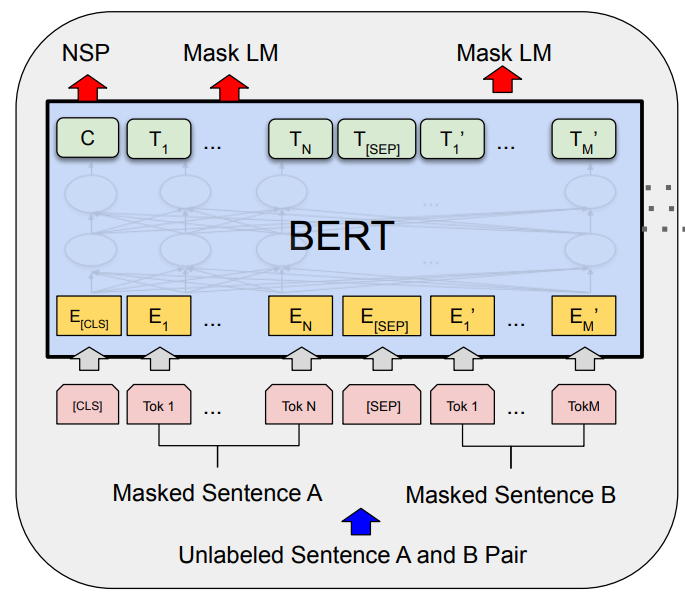
- Het “Pre-trainen” van een algemeen BERT model op domein specifieke documenten. Hierbij leert het model welke terminologie binnen het domein gebruikt wordt en wat bepaalde termen binnen het domein betekenen. Bij deze taak gaat het om verzamelen en snel verwerken van zeer grote data hoeveelheden. Hiervoor is specialistische kennis en hardware onontbeerlijk.
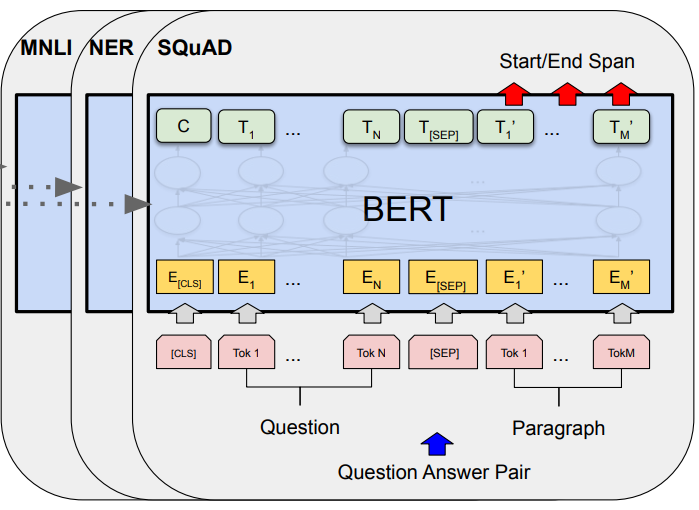
- Het “Finetunen” van een domeinspecifiek BERT model om een bepaalde NLP taak uit te voeren. Afhankelijk van de beoogde toepassing kan dit een sentence classifier zijn (van eenvoudig binair sentiment tot multi label – multiclass), een token classifier (voor bijvoorbeeld named entity recognition of part of speech tagging), multi sequence classifier (voor entailment classification) of een zogenaamde sequence to sequence classifier (summarization, translation, question answering etc.)
- Tenslotte moet moet het model nog worden ingebed in de software waarmee de gebruiker de beoogde interacties kan uitvoeren. Dit kan variëren van een webservice waar vanuit een enterprise systeem documenten worden aangeboden, verwerkt en het resultaat als metadata wordt teruggestuurd, tot een volledige applicatie met een user interface voor bijvoorbeeld het snel semantisch doorzoeken van een document corpus.
Heeft u vragen naar aanleiding van dit product of wilt u een kosteloze demonstratie, neem dan contact met ons op.
in English
Within Semlab we already have 20 years of experience in the automatic processing of Dutch texts. We use a hybrid approach that is based on ontology-driven natural language analysis on the one hand and language modeling on the other. The latter has recently taken off with the development of so-called language models based on transformers such as BERT and RoBERTa.
The core of this development is that it is now possible to use the general language models developed by parties such as Microsoft, Google and Facebook, which are trained on specialized hardware and extremely large data sets. These language models can be used as a basis for specific NLP applications.
At Semlab we have specialized in adapting these language models to practical applications for our customers. This roughly boils down to the following tasks:
- The “Pre-training” of a general BERT model on domain specific documents. The model learns which terminology is used within the domain and what specific terms mean within the domain. This task involves collecting and processing very large amounts of data quickly. Specialist knowledge and dedicated hardware are indispensable for this.
- Fine-tuning a domain-specific BERT model to perform a particular NLP task. Depending on the intended application, this can be a sentence classifier (from simple binary sentiment to multi label – multiclass), a token classifier (for e.g. named entity recognition or part or speech tagging), multi sequence classifier (for entailment classification) or a so-called sequence to sequence classifier (summarization, translation, question answering etc.)
- Finally, the model still needs to be embedded in software that allows the user to perform their intended interactions. This can range from web services to which documents are offered, processed and the result is returned as metadata to an enterprise system, to a complete application including a user interface for, for example, thorough semantic research within a document corpus.
If you have any questions about this product or if you would like a free demonstration, please contact us.